
Bias in AI: Cognitive bias in machine learning
AI Bias: inherent flaw or mere side effect!
Originally Published April 18, 2018
Introduction
Artificial Intelligence is broadly referred to as any source, channel, device or usage application whereby tasks normally attributed to human intelligence, such as reasoning, interpretation of facts, storage and deduction of information from such facts and ultimately, decision making is reproduced outside human body and human networks.
According to a Forbes article, as technology, and, importantly, our understanding of how our minds work, has progressed, our concept of what constitutes AI has changed. Rather than increasingly complex calculations, work in the field of AI has concentrated on mimicking human decision making processes and carrying out tasks in ever more human ways.
Artificial Intelligence uses are influencing people’s lives in more ways than can be counted. Autopilots in aviation is possibly one of the earliest uses of AI. Most airline captains trust auto pilot for 95% of time during an actual typical flight. AI is behind the personal virtual assistants in the iPhones, Google Home, and Amazon Echo. AI is used to recommend shopping products and brands based on past choices and history of website viewing. AI is being used to develop driver-less cars to make commuting faster and safer. It is used to recommend shows or films according to viewer’s tastes, preferences and past choices on Netflix or what songs one may like to listen to on Spotify. AI is used to how products are marketed and customized according to target audience’s tastes and preferences while steering conversations uses have with their favorite retailers, and will be used to transform retail industry around the world.
In recent interviews, Uber’s Head of Machine Learning Danny Lange confirmed Uber’s use of machine learning for its popular features like ETAs for rides, estimated meal delivery times on UberEATS, computing optimal pickup locations, as well as for fraud detection. The pioneering research behind these features is what sets Uber different from its competitors, its executives feel. And while users ultimately get to decide that, there is no doubt that AI powered applications are not just part of the ecosystem, rather form an ecosystem of their own, which is continually expanding equally in its size and impact.

Image Credit: Psychology roots
What is Artificial Intelligence?
Artificial intelligence then in other words is simply the reproduction of human intelligence and capabilities outside the human body. The work that can be done by machines or mechanical applications or software programs carrying out very basic rudimentary and rule based decision making can be termed as Artificial Intelligence. We regularly interface with such systems on a daily basis – airline ticketing and check in systems; chat bots and intelligent IVRs replacing customer service agents; human profiling software and applications flagging any abnormal profile or profile that fits one or more among the list of many criterion for detailed human checks; banking sector applications where any abnormal transaction falling outside a pattern is flagged for manual checks are a few among immeasurable applications of Artificial intelligence. Basically, any task done by humans which involved repetitive application of mind and knowledge, can be handled to automated processes or devices. This is also known as applied AI.
As humans grow and learn newer things, apply their knowledge and continue to learn thereby expanding both the repository of knowledge and their understanding of such repository, i.e. the breadth and width of subject matter, a credible and reliable Artificial Intelligence system must have the ability to learn continually based on the amount of information available to it at any given time. As early as 1959, thinkers laid down this expectation – that its simple to teach computers how to learn, rather than teaching them everything they need to know.
As internet became common during 1990s and 2000s, the emergence of huge troves of data, and availability of such data for analysis in order to learn human needs, even before humans themselves could understand those needs, has become the new future of Information Technology. Technology is no more just to aid humans, but has the potential today to govern every aspect of human lives. And this is a trend which is only growing and becoming more pervading than ever before. The data collected today is not just about humans, but its also about the machines which collect data about humans themselves. Data from a source is not just about that source alone, but contains many different layers of abstraction providing many useful insights not just in to the primary purpose of study but in to related fields as well.
However there is another aspect of Artificial Intelligence – generalized AI. This aspect caters to much deeper, and perhaps is the truest representation of artificial intelligence. Generalized AI is what was responsible for field of study like Machine Learning and Neural Networks, both of which are central to the idea of Artificial Intelligence. The generalized AI is powered by new concepts like deep learning. The invention of deep learning, a technique which uses special computer programs called neural networks to churn through large volumes of data and is trained to identify and remember patterns in that data set, means that technology which gives a good impression of being intelligent is spreading rapidly.
Machine learning is a sub-field or an application of AI. This involves feeding tons of data gradually – whether it’s in the form of text, images or voice – and adding a classifier to this data. An example would be showing the computer an image of a woman working in an office and then labelling this as woman office worker. Over time and with addition of multiple parameters for each data set and complicated algorithms, the system will learn to make predictions based on the data it is reading. These predictions follow certain rule sets, specified and hard coded in to the machine on the basis of which decisions are made, while simultaneously also becoming inputs in to accuracy analysis to improve decision making for future data sets.
The neural networks are the newest and possibly the most exciting layer within Artificial Intelligence that is powering a new breed of research and machine learning. This new breed of deep machine learning is inspired by the natural evolution of human brain and its connected neurons. The neuron networks use a series of interconnected units or processors and are adaptive systems that can adjust their outputs based on doing, essentially ‘learning’ by example and past data sets as they go, adapting their behavior based on results. This mimics evolution in the natural world, but at a much faster pace, with the algorithms quickly adapting to the patterns and results discovered to become increasingly accurate and valid.
Image Credit : Internet
Neural networks can identify patterns and trends among data that would be too difficult or time-consuming to deduce through human research (picture going through millions of data sets and sub-sets), consequently creating outputs that would otherwise be too complex to manually code using traditional programming techniques.
And as the technology progresses and becomes ever-more complex and autonomous, it also becomes harder to understand, not just for the end users, but even for the people who built the platforms in the first place. This has raised concerns about a lack of accountability, hidden biases, and the ability to have clear visibility of what is driving life-changing decisions and courses of action. This is commonly referred to as Black Box in Artificial Intelligence, where what goes in (inputs) and what comes out (output) is visible and transparent, yet the process followed by the machine or what goes on inside the machine (the brain) is not visible. Scientists and data researchers are not able to pinpoint what learning are being adapted by the machine, though the outputs being produced are desirable.
Bias in Artificial Intelligence
AI Applications range from intelligent IVRs, data analytics, speech-to-text transcription to healthcare where it is being used in myriad of ways including detecting early signs of blindness. AI now runs quality control in factories and cooling systems in data centers. States hope to employ AI to recognize threat from terrorist propaganda sites and remove them from the web. AI is central to attempts to develop self-driving vehicles. Among the ten most valuable quoted companies in the world, seven say they have plans to put deep-learning-based AI at the heart of their operations in future or are already doing so.
Machine Learning and neuron networks are interchangeably used within Artificial Intelligence ecosystems as these represent the way AI is progressing to meet the demands from technology savvy businesses and individuals. Often, these networks create what are known as black boxes, referring to closely guarded virtual boundaries where the internal branching, logic application and evolution of the application itself is obfuscated from public view. And as is often seen, many of the AI algorithms involve use of facial recognition technology, which is deeply flawed in itself. Facial recognition technology (FRT) which aims to analyze video, photos, thermal captures, or other imaging inputs to identify or verify a unique individual is increasingly infiltrating our lives. Facial recognition systems are being provided to airports, schools, hospitals, stadiums, shops, and can readily be applied to existing cameras systems installed in public and private spaces.

Additionally, there are already documented cases of the use of FRT by government entities that breach the civil liberties of civilians through invasive surveillance and targeting. Facial recognition systems can power mass face surveillance for the government – and already there are documented excesses, such as explicit minority profiling in China and undue police harassment in the UK. Source: Facial Recognition Technology (Part 1):
Its Impact on our Civil Rights and Liberties, report issued by United States House Committee on Oversight and Government Reform dated May 22, 2019
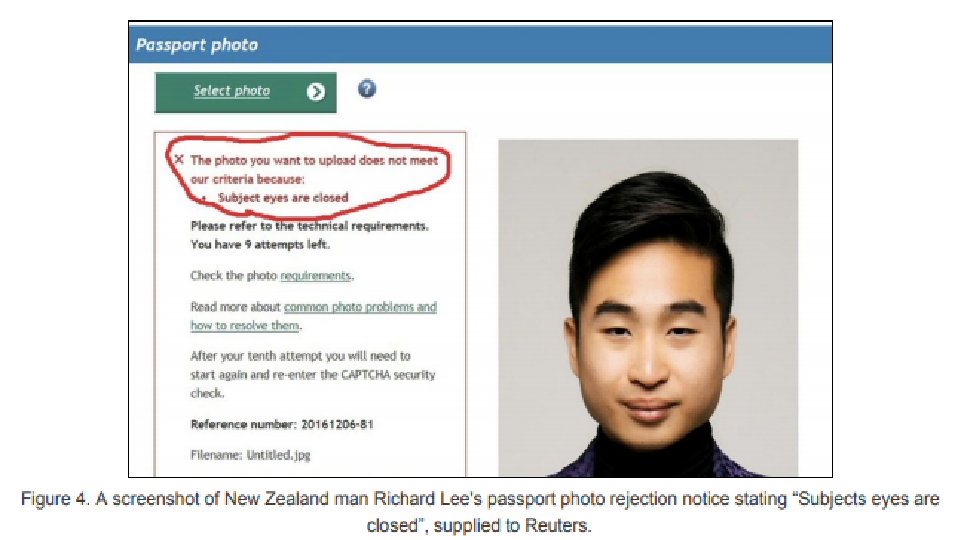
Reuters reported a case where a New Zealand man of Asian descent had his photo rejected by an online passport photo checker run by New Zealand’s department of internal affairs. The facial recognition systems registered his eyes as being closed by mistake. When government agencies attempt to integrate facial recognition into verification processes phenotypic and demographic bias can lead to a denial of services that the government has an obligation to make accessible to all constituents. Source: Facial Recognition Technology (Part 1):
Its Impact on our Civil Rights and Liberties, report issued by United States House Committee on Oversight and Government Reform dated May 22, 2019.
People are often too willing to trust in Artificial Intelligence applications, or machine learning mathematical models because they believe that these systems will remove human bias. However, as the machine algorithms and systems replace human processes, these machines are not generally held to similar standards. A big part of the problem is that individuals and companies that develop and apply machine learning systems, and Government regulators who have the mandate to govern the usage, show little interest in monitoring and limiting algorithmic bias. Financial and technology companies use all sorts of mathematical models and aren’t transparent about how they operate.
As with most new technologies, the research wings of the Armed Forces made initial forays in to teaching machines how to do human jobs that involved at the very least a complex application of information abstraction – or as we know it today, Artificial Intelligence and Machine Learning. From the early days of attempted use of AI and Machine Learning applications, a widely circulated though highly improbable or at the very least exaggerated, parable has been told and retold multiple times in forums as wide as coffee table discussions to online articles and research papers. While the story itself may be apocryphal, an almost impossible number of sources citing the story has given it a legendary description. Some researchers attribute this story to a paper published in 1964, almost 5 decades before concept of Artificial intelligence, machine learning etc became common.

Image Credit: Dilbert
For an amusing and dramatic case of creative but unintelligent generalization, consider the legend of one of connectionism’s first applications. In the early days of the ‘perceptron’ the army decided to train an artificial neural network to recognize tanks partly hidden behind trees in the woods. They took a number of pictures of a woods without tanks, and then pictures of the same woods with tanks clearly sticking out from behind trees. They then trained a net to discriminate the two classes of pictures. The results were impressive, and the army was even more impressed when it turned out that the net could generalize its knowledge to pictures from each set that had not been used in training the net. Just to make sure that the net had indeed learned to recognize partially hidden tanks, however, the researchers took some more pictures in the same woods and showed them to the trained net. They were shocked and depressed to find that with the new pictures the net totally failed to discriminate between pictures of trees with partially concealed tanks behind them and just plain trees. The mystery was finally solved when someone noticed that the training pictures of the woods without tanks were taken on a cloudy day, whereas those with tanks were taken on a sunny day. The net had learned to recognize and generalize the difference between a woods with and without shadows!
This bias is not limited to just one study or research project, nor is it an isolated phenomena. Whenever there is a dataset of human decisions, it naturally includes bias. This bias can manifest in many ways and could include hiring decisions, grading student exams, medical diagnosis, loan approvals, etc. In fact anything described in text, in image or in voice requires information processing – and this will be influenced by cultural, gender or race biases.

Image Credit: upliftconnect
One example of AI systems is in financial industry, where complicated algorithms assess credit worthiness and credit risk before issuing credit cards or approving small loans. The task is to filter clients in order to avoid processing any that are likely to fail to make payments. Using data of declined clients, history of bad debts, or delinquencies and associating them with a set of rules could easily provide basis of decisions that machine could produce without human intervention. However, this could also lead to biases getting built in to the system, for example, applications from certain section of people are seen to have higher rejection rates based either on their employment type or simply, gender.
The financial industry is not alone in observing these biases creeping in. LinkedIn, the popular professional and career website, for instance, had an issue where highly-paid jobs were not displayed as frequently for searches by women as they were for men because of the way its algorithms were written. This gender based discrimination came about as the initial users of the site’s job search function were predominantly male for these high-paying jobs so the machine learning aspect just ended up proposing these jobs to men – thereby simply reinforcing the bias against women
The concerns of biases creeping in are not only limited to lower level, data centric and rule based tasks in applications. These concerns are equally, and perhaps more dangerously manifested within the uses of deep machine learning that requires minimal guidance, but ‘learns’ as it goes through identifying patterns from the data and information it can access. Its use of neural networks and evolutionary algorithms resembles a tangled mess of connections that are nearly impossible for analysts to disassemble and fully understand.
As explained earlier, this lack of understanding leads to pervasive fears of something unknown lurking just beneath the surface. The nearly non-transparent ways in which the deep learning machines itself ‘learn’ to navigate our worlds, at the very least, demand closer inspection in order to be fully understood, if not fully trusted.

Image Credit: Internet
Another relevant real world example here is of how Google ranks search results. This is a notoriously secret formula, and has been the subject of countless allegations of anti-trust movements, conjectures of how the system manipulates search results and other far more wild theories. Digital agencies and professionals have made and continue to make careers out of their own interpretation of the rules of the game, trying to deliver what they think Google wants to be able to boost their rankings. Many functions are powered by complex algorithms, code, programming or servers, and yet are still deemed trustworthy enough for investing large chunks of the marketing budget.
A system called COMPAS, made by a company called Northpointe, offers to predict defendants’ likelihood of reoffending, and is used by some judges to determine whether an inmate is granted parole. The working details of this program are guarded under heavy veils of secrecy, but an investigation by ProPublica found evidence that the model may be biased against minorities.
The much touted facial recognition algorithm used by various products and applications worked for perfectly for lighter-skinned subjects, however it couldn’t recognize many pictures of people with darker complexion. It’s not a unique problem; in 2015, a Google algorithm classified faces of black people as gorillas.
There have been calls to end the use of ‘black box’ algorithms in government because, without true clarity on how they work, there can be no accountability for decisions that affect the public. Fears have also been raised over the use of bias within decision-making algorithms, but with a perceived lack of a due process in place to prevent or protect against this.

Image Credit: Internet
Bias Elimination: Is it possible?
As deep learning systems, neural networks and machines become capable of performing profound and abstract functions, the fear from AI going rampant becomes more real. The real fear stems not so much from the machines suddenly stop obeying humans or start behaving of their own volition, or at least attempt to do so, rather the real fear arises from the fact that machines do exactly what they are told to do but do so in an incomprehensible manner where creators and users of the technology do not have any visibility and hence lack control. The reason behind this fear is simple – the deep learning networks are taught (LEARN) to rearrange their digital processes in response to the data ingested. The bits of computer code within the neuron networks is designed to copy the way human brains work, by drawing connections between events and information. This implies that once the network is designed and trained, even the creators of the network have little control or even visibility in to what it is doing. Of course, permitting such machines and systems to make critical decisions, be it in financial or healthcare industries or anywhere else, amounts to putting human lives in to the hands of machines, the working and operations of which are still not fully understood. It is akin to a beta program being allowed to fly jet full of passengers and cargo over densely populated areas, and though there are pilots present in the cockpit, their role is reduced to observers’ role.
In a MIT Technology review article from October 2017 titled Forget Killer Robots—Bias Is the Real AI Danger, the problem of bias in machine learning is likely to become more significant as the technology spreads to critical areas like medicine and law, and as more people without a deep technical understanding are tasked with deploying it. Some experts warn that algorithmic bias is already pervasive in many industries, and that almost no one is making an effort to identify or correct it
To rid the AI and deep machine learning from these biases is a complex proposition. As previously discussed, these biases exist due to multiple factors, from type of use of application, to data based biases, to people based reasons, and finally due to a regulatory apathy.
Data based biases general refer to biases included in AI applications and machine learning due to un-clean, poor quality data with biased results already included being uploaded in to a system. This is no brain-teaser, as ‘Garbage in-Garbage out’ is a pretty well-known pitfall.
People based biases generally refer to biases arising out of how interpretation of business rules and data parameters is decided, as well as disinterested stakeholders who are interested in the bottom line and not ridding the AI applications and machine learning systems of long term health and transparency.
Biases due to type of application refer generally to usage based biases and lack of transparency depending largely on the industry type. For example, security, finance and healthcare generally tend to operate with largely secretive processes and restrict access to their processes and systems to any outsiders making it difficult to detect such biases.
Finally, lack of any regulatory oversight, is seen as the final nail in the coffin. The overall perception is that biased algorithms and systems are everywhere, yet no one seems to care. In-house regulators are generally under significant pressure to minimize any application downtime or to suggest expensive fixes. External watchdogs generally lack teeth, while those external regulators who wield some kind of power primarily through policy formulation, typically government agencies, are seldom interested in regulating the uses of AI and machine learning. And while the Congress may be rightly worried about the threats of this unknown equation, the progress seems to be slower and farther than what is needed.
Artificial Intelligence applications suffer from a natural, lack of diversity which in many cases is indicative of deep-rooted cultural norms. AI assistants like Apple’s Siri or Amazon’s Alexa have default female names, voices, and personas, are largely seen as helpful or passive supporters of a user’s lifestyle due in part to their personal messaging and in part to their shopping list task orientation. Meanwhile, their counterparts like IBM’s Watson or Salesforce’s Einstein are perceived as complex problem-solvers tackling global issues, perhaps in part at least due to their male-branded disposition and in part due to their outward problem solving approach. The quickest way to flip this public perception on its head is to render AI genderless. The more long-term approach requires expanding the talent pool of people working on the next generation of AI applications and machine learning technologies to include multiple viewpoints and dispositions in producing a homogenous product, which is culturally neutral yet sensitive to audiences’ diverse requirements.
Another approach is to introduce adequate ‘Bias’ testing before releasing any new version of an existing AI application. Software and application testing is already pretty standardized functions within software development processes, however bias testing is something which is still unknown even among the technology giants. Bias testing must become de-facto for AI applications, while for continually learning machine learning or deep learning applications, the machine or the system must be made complaint to run ‘Bias’ testing standards before fresh automated deployments, or in other cases at regular, frequent intervals, for example, once every 15 days or 30 days depending on the feasibility.

Image Credit: TNW
Conclusion
Facebook’s news feed algorithm can certainly shape the public perception of events, social interactions and even major news events. Other algorithms may already be subtly distorting the kinds of medical care a person receives, or how they get treated in the criminal justice system. Most of the times the biases in AI are not well-known, these may be subtle, hard to notice under the surface ripples which even when noticed are generally dismissed as non-events. On other occasions the biases may not be even shared publically, partly due to non-discovery and partly due to illicit attempts at fix-the-problem before-it-gets-out-of-hand approach.
In real terms, the threat from AI is perhaps not as serious as its usually portrayed in books or movies. However it doesn’t take much for the threat to be manifested in the present day, rather than at some indeterminable date in future. That is the biggest threat of AI where many believe that the AI applications and systems today have the potential to spin uncontrollably out of hands of their creators and users.
As AI is used to produce more meaningful results and power more and more high profile and public facing services, such as self-driving cars, medical treatment suggestions, early warning systems in fields such as oil exploration, or automated defense systems, concerns have understandably been raised about what is going on behind the scenes. If people are willing to put their lives in the hands of AI-powered and machine learning applications, then they would want to be sure that someone understands how the technology works, how in-built biases take effect and how it powers decisions, and more importantly, that someone has the power and means to remove these biases or at least restrict the applications if the biases get out of hand, or if the need arises in any other manner.