The impact of Bias in Artificial Intelligence!
Originally Published April 21, 2018
Artificial Intelligence is broadly referred to as any source, channel, device or usage application whereby tasks normally attributed to human intelligence, such as reasoning, interpretation, storage and processing of information, ability to analyze historical information and ultimately, decision making is reproduced outside human body and human networks.
Classic machine learning algorithms involve techniques such as decision trees and association rule learning, including market basket analysis (ie, customers who bought Y also bought Z). Deep learning, a subset of machine learning that includes neural networks, attempts to model brain architecture through the use of multiple, overlaying models.
Classic examples of Machine learning include Virtual Personal Assistants like Siri, Alexa, Google, Predictions while Commuting, Videos Surveillance, Social Media Services from personalizing your news feed to better ads targeting, Face recognition, Email Spam and Malware Filtering, Online Customer Support including chat bots, Search Engine Result Refining, Product Recommendations based on previous purchase trends, and Online Fraud Detection including efforts to curb money laundering.
From a technology and computer science perspective, bias may refer to the productive bias that enables Machine Learning, both at the level of selecting the training data-set and at the level of training the algorithms. It reminds one of David Wolpert’s ‘no free lunch theorem’. This relates to the trade-off between the size of a training data-set, its relevance, the types of algorithms used, and the accuracy and/or speed of the results. Machine learning research designs involve a number of tradeoffs between e.g. speed, predictive accuracy, over-fitting (low utility) or overgeneralizing (blind
spots), confirming that each choice amongst competing strategies has a cost: there is no free lunch as to the research design for machine learning. From a societal perspective, bias may refer to unfair treatment or even unlawful discrimination. It is crucial to distinguish inherent computational bias from the unwarranted impact of unfair or wrongful bias, while teasing out where they meet and how they interact. This includes an inquiry into the ethical assessments of ML bias, based on the fact that ML applications are re-configuring the ‘choice architectures’ of our online and offline environments. The blind application of machine learning runs the risk of amplifying biases present in data.
The underlying assumption of any machine learning program is the existence of an ideal target function or a perfect equation that determines the relationship between input data (e.g., the position of the pieces or board state) and output data (winning or losing the game). In respect to a game of chess, this assumption may hold true, but once we move from chess to human behaviors that are not constrained by a set of unambiguous rules this assumption of a perfect equation is simply wrong.
The word ‘bias’ has an established normative meaning in legal language, where it refers to ‘judgement based on preconceived notions or prejudices, as opposed to the impartial evaluation of facts’. The world around us is often described as biased in this sense, and since most machine learning techniques simply mimic large amounts of observations of the world, it should come as no surprise that the resulting systems also express the same bias
Human biases are well-documented, from implicit association tests that demonstrate biases we may not even be aware of, to field experiments that demonstrate how much these biases can affect outcomes.
Removing bias from AI is the result of deliberate, calculated and thought-out human endeavors, and certainly not an unintended byproduct of certain data analysis. Companies employing any or all five forms of AI — computer vision, natural language, virtual assistants, robotic process automation, and advanced machine learning — must realize that any output they hope to derive are only as good as the data on which the applications are trained.

Picture Credit: Google Images
Technical breakthroughs and demand for turnkey solutions has led developers to build and deploy platforms where machine-learning engines are made readily available with little or almost no investment in expensive programming teams. AWS or Amazon Web Services recently launched a “machine learning in a box” offering called SageMaker, which non-technical folk can leverage to build sophisticated machine-learning models, and Microsoft Azure’s machine-learning platform, Machine Learning Studio, doesn’t require extensive coding.
The intelligent, self-driving systems which rely on complicated algorithms to produce outcomes are as susceptible to the biases as the humans themselves. Just as the human brain builds a model of the world based on what information is fed to it, the algorithms behind machine learning systems and artificial intelligence as a whole build a model world, their own version of reality, based on the data fed to it. If a system is trained on one set of data which is overloaded with samples from a given dataset, the system will have a hard time recognizing other sets of equally valid data. Even in cases where the system is fed large amount of data of several different types, the problem persists as the data may not be deep enough for the system to make unbiased decisions.
In a small example of this bias, Google’s photo app, which can apply automatic labels to pictures in digital photo albums, classified images of black people as gorillas. Similarly, Nikon’s camera software misread images of Asian people as blinking. Of course these errors are not intentional, nor are they serious enough to give rise to widespread concerns, yet the bias of these systems has led people to question, perhaps legitimately so, the blind faith many place on artificial intelligence.

Picture Credit: Google Images
The models learn precisely what they are taught
Considering Bias while feeding data in to machine learning applications is almost becoming a pre-requisite to deploying a machine learning application and is not considered an optional refinement any longer. While machine learning systems enable efficiencies and offer advantages of breakthrough processes, there are many ways in which machines can be taught to do something immoral, unethical, or just plain wrong.
To detect the biases in Machine Learning, it is essential to understand how Machine learning actually works, and to detect the series of design choices that inform the accuracy of the outcome. Its essential to understand that each of the design choices that went in to framing the Machine Learning algorithm, entails real life trade-offs that determine the relevance, validity and reliability of the algorithm’s accuracy for real life problems.
In one of the early examples of algorithmic bias, 60 women and ethnic minorities were denied entry to St. George’s Hospital Medical School per year from 1982 to 1986, because of a new computer-guidance assessment system that denied entry to women and men with “foreign-sounding names” based on historical trends in admissions.
Machine learning in health care holds great promise as it means the avoidance of biases in diagnosis and treatment thereby improving not only the availability of care but the actual results. Health care providers and Practitioners may have bias in their diagnostic or therapeutic decision making. This human bias may be circumvented if a computer algorithm could objectively synthesize and interpret the data in the medical record and offer clinical decision support to aid or guide diagnosis and treatment. In Healthcare, the integration of machine learning with clinical decision support tools, such as computerized alerts or diagnostic support, may offer targeted and timely information that can improve clinical decisions to health care providers, doctors and nurses. Machine learning algorithms, however, as it is time and often seen are subject to biases. These biases include those related to missing data and patients not identified by algorithms, sample size and underestimation, and mis-classification and measurement error. Given many such examples, there is a growing concern that biases and deficiencies in the data used by machine learning algorithms may contribute to socioeconomic disparities in health care.
Types of Biases
Lets look at some of the basic types of biases primarily only related to datasets used to train machine learning algorithms.
Anchoring bias occurs when choices on metrics and data are based on personal experience or preference for a specific set of data. By “anchoring” to this preference, models are built on the preferred set, which could be incomplete or even contain incorrect data leading to invalid results. Because this is the “preferred” standard, realizing the outcome is invalid or contradictory and can be hard to discover.
Availability bias, similar to anchoring, is when the data set contains information based on what the modeler’s most aware of. For example, if the facility collecting the data specializes in a particular demographic or co-morbidity, the data set will be heavily weighted towards that information. If this set is then applied elsewhere, the generated model may recommend incorrect procedures or ignore possible outcomes because of the limited availability of the original data source.
Confirmation bias leads to the tendency to choose source data or model results that align with currently held beliefs or hypotheses. The generated results and output of the model can also strengthen the confirmation bias of the end-user, leading to bad outcomes.
Stability bias is driven by the belief that large changes typically do not occur, so non-conforming results are ignored, thrown out or re-modeled to conform back to the expected behavior. Even if we are feeding our models good data, the results may not align with our beliefs. It can be easy to ignore the real results.
Machines are generally held to be more trustworthy than humans. While a currency counting machine is definitely more accurate and faster than a person counting currency with bare hands, it is difficult to extrapolate the same level of trust to machines with active learning and thinking functions.
A look at Allegheny Family Screening Tool: unfairly biased, but well-designed and mitigated
In this final example, we discuss a model built from unfairly discriminatory data, but the unwanted bias may be mitigated in several ways. The Allegheny Family Screening Tool is a model designed to assist humans in deciding whether a child should be removed from their family because of abusive circumstances. The tool was designed openly and transparently with public forums and opportunities to find flaws and inequities in the software.
The unwanted bias in the model stems from a public dataset that reflects broader societal prejudices. Middle- and upper-class families have a higher ability to “hide” abuse by using private health providers. Referrals to Allegheny County occur over three times as often for African-American and biracial families than white families. Commentators like Virginia Eubanks and Ellen Broad have claimed that data issues like these can only be fixed if society is fixed, a task beyond any single engineer.
Machine Learning and neuron networks are interchangeably used within Artificial Intelligence ecosystems as these represent the way AI is progressing to meet the demands from technology savvy businesses and individuals. Often, these networks create what are known as black boxes, referring to closely guarded virtual boundaries where the internal branching, logic application and evolution of the application itself is obfuscated from public view. And as is often seen, many of the AI algorithms involve use of facial recognition technology, which is deeply flawed in itself. Facial recognition technology (FRT) which aims to analyze video, photos, thermal captures, or other imaging inputs to identify or verify a unique individual is increasingly infiltrating our lives. Facial recognition systems are being provided to airports, schools, hospitals, stadiums, shops, and can readily be applied to existing cameras systems installed in public and private spaces.

Additionally, there are already documented cases of the use of FRT by government entities that breach the civil liberties of civilians through invasive surveillance and targeting. Facial recognition systems can power mass face surveillance for the government – and already there are documented excesses, such as explicit minority profiling in China and undue police harassment in the UK. Source: Facial Recognition Technology (Part 1):
Its Impact on our Civil Rights and Liberties, report issued by United States House Committee on Oversight and Government Reform dated May 22, 2019
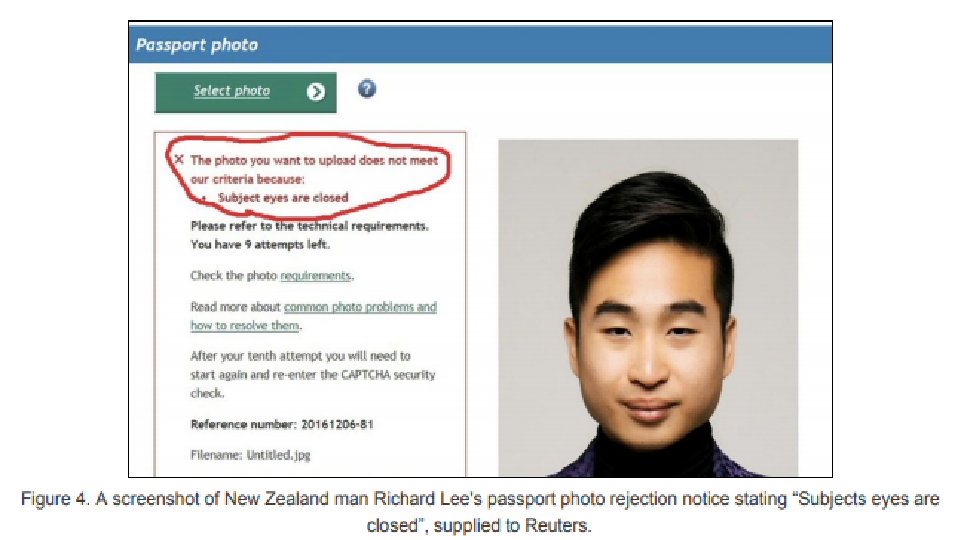
Reuters reported a case where a New Zealand man of Asian descent had his photo rejected by an online passport photo checker run by New Zealand’s department of internal affairs. The facial recognition systems registered his eyes as being closed by mistake. When government agencies attempt to integrate facial recognition into verification processes phenotypic and demographic bias can lead to a denial of services that the government has an obligation to make accessible to all constituents. Source: Facial Recognition Technology (Part 1):
Its Impact on our Civil Rights and Liberties, report issued by United States House Committee on Oversight and Government Reform dated May 22, 2019
In an investigative study published by ProPublica, the investigators found glaring gaps in how a widely used software that assessed the risk of recidivism in criminals was twice as likely to mistakenly flag black defendants as being at a higher risk of committing future crimes. In other words, simply based on the color of the skin, a machine learnt to classify someone as high risk, precisely similar to what some humans would do.
Predictive programs like the one quoted above have generally a higher chance to predicting an outcome on the basis of purely historical data biases leading to re-enforcement of those same biases. In yet another example, in many cities including New York, Los Angeles, Chicago and Miami, law enforcement agencies are using software analyses of large sets of historical crime data to forecast where crime hot spots are most likely to emerge. These areas are then policed heavily in what many argue to be perpetuation of an already vicious cycle of policing over-policed areas to detect and detain more criminals, while crimes in other parts of the city, predominantly white neighborhoods, go relatively undetected.

Picture Credit: Google Images
AI has been widely used to assess standardized testing in the United States and recent studies suggest that it could yield unfavorable results for certain demographic groups. AI also plays deciding role in hiring decisions, with up to 72% of resumes in the US never being viewed by a human.
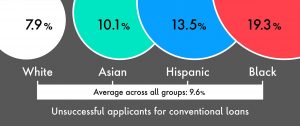
As recently as 2017, data from the Home Mortgage Disclosure Act showed that applicants from African-Americans are three times as likely and applicants from Hispanic descent are two times more likely to get rejects for conventional loans.
In more examples, Amazon’s much touted same day delivery service was made unavailable to residents in certain communities based on similar biases in the past, while women job searchers were less likely to see higher paid job ads in results to their job search queries on Google’s search engine than their male counterparts. Both these examples indicate an undesirable outcome for the target audience – though it remains a matter of some speculation if these errors are indicators of broad systemic biases or just glitches in how ad results are displayed at least in Google’s case. Regardless of its findings, the studies that found these errors and biases indicate that there are more, unknown biases occurring out there which are yet to be discovered.

Lets take a look at Fixing AI Biases
To address potential machine-learning bias, the first step is to adapt transparent means to judge what preconceptions could possibly influence decisions based on a given set of data or what biases currently exist in an organization’s processes, and actively hunt for how those biases might manifest themselves in data. Since this can be a delicate issue, many organizations bring in professionals and external experts to analyze their past and current practices.
Up until 10 years ago, the problems of bad or biased data-sets leading to unfair and / or incorrect outcomes was not even considered. The focus was on speed and agility – to build and release systems faster.
On the one hand, many people seem to believe that machine learning is agnostic, in the sense of being oblivious to human bias or independent of the design choices that determine its performance accuracy. In that sense, however, machine learning is not agnostic. On the other hand, many people seem to believe that undesirable bias in the training data can be remedied in a straightforward way, thus restoring some kind of neutral
training set, resulting in agnostic machine learning.
The errors of intelligent systems are hardly noticeable to most people, yet the presence of similar trends based on data in both historical cases and today’s artificial intelligence systems indicates a deeper malice – something which has gone unnoticed and made its way to how the machines think and act. The problem emerges as the algorithms learn, evolving in to newer and uncharted courses or neuron networks, and take the shape of something which was unimaginable to begin with.

Picture Credit: Google Images
Breaking the ‘black boxes’ refers to revealing and explaining the ways in which machine learning and neuron networks arrive at data outputs. However this is largely inhibited by the lack of transparency by AI applications to make its entire search parameters and logics open to scrutiny which adds to growing complexity and skepticism around the entire ecosystem of AI. A closer inspection of the prevalent issues within AI makes one fact painfully obvious – Governments and public institutions as well as private individuals need to do more, not just appear to be doing so, but actually undertake conscious initiatives to establish accountability in the system. Most importantly, as the enterprises invest in predictive technologies, they must commit to fairness, due process and transparency.
Posing the following questions can help researchers check for systematic bias in underlying data:
- Presence of particular groups suffering from systematic data error or ignorance?
- Have the researchers intentionally or unintentionally ignored any group?
- Are all groups represented proportionally broadly, for example considering an attribute like protected feature of race, are all races being identified or merely one or two?
- Has the research team done enough contextual work, for example identifying enough features to explain minority groups?
- Has the research team used or is likely to use or create features that are tainted?
- Has the research team considered stereotyping features?
- Are the data models apt for underlined use case?
- Is the data model accuracy similar for all groups under study?
- Has the research team identified and corrected predictions that are skewed towards certain groups?
- Has the research team optimized all required metrics and not just those that suit the business or potential favorable outcome/s?
Finally, just an effort to focus on ethics alone will not do when confronting the framing powers of machine bias, highlighting the need to bring the design choice that determine these framing powers under the Rule of Law.
By carefully altering the way different data-sets and groups are assigned to protected or sensitive classes, and ensuring these groups have equal predictive values and equality across false positive and false negative rates, the research team can better detect bias in AI.
Humans first: Collective enthusiasm for applying computer technology to every aspect of life has resulted in a tremendous amount of poorly or hastily designed systems. People and companies are so eager to do everything digitally — hiring, driving, paying bills, even choosing romantic partners — that they have stopped demanding that technology actually work to advance the needs of people for whom the technology is created. There are fundamental limits to what humans can and should do with technology.
Establishing Anchors: Many applications of machine learning actually work with a so-called “ground truth” to anchor the performance metric; to test whether the system gets it right, machine learning will often require a machine-readable indication of what is “right.” The ground truth is, for instance, based on surveys or interviews where people are asked to assess their own position, emotions, or preferences or, alternatively, based on expert opinion such as medical diagnoses made by medical doctors.
Accounting for adversarial training in training phase of Machine Learning -: Adversarial examples exploit the way artificial intelligence algorithms work to disrupt the behavior of artificial intelligence algorithms. In the past few years, adversarial machine learning has become an active area of research as the role of AI continues to grow in many of the applications we use. In adversarial training, the engineers of the machine learning algorithm retrain their models on adversarial examples to make them robust against perturbations in the data. There’s growing concern that vulnerabilities in machine learning systems can be exploited for malicious purposes.
Business Rules, Legal, Regulatory and Compliance framework: Refusing credit, flexible pricing or raising an insurance premium may be based on the freedom to contract, but that freedom is not unlimited and consumer law, competition law, financial services law and insurance law may stipulate further restrictions that must be met, potentially requiring a motivation for a refusal or specific types of price differentiation.
Rigorous Testing, Analysis and Adjustments: The study of trade-offs is an important element in the journey to reduce biases. Machine learning research designs involve a number of trade-offs between e.g. speed, predictive accuracy, over-fitting (low utility) or overgeneralizing (blind spots), confirming that each choice amongst competing strategies can be leveraged to tweak the outcome. Is speed more important, or accuracy? Is color of skin given higher weight, or anatomical features? Do bodily movements mean anything? The more important applications should be based on confirmatory research that includes inquiry into causality, so as to prevent delusional inferences that are wrongly taken for granted precisely because there is no understanding of the causal dependencies on potentially unknown parameters.
A crucial way to test for biases is by stress-testing the system as demonstrated by computer scientist Anupam Datta of Carnegie Mellon University who designed a program to test whether AI showed bias in hiring new employees. Machine learning can be used to pre-select candidates based on score arrived at through considering various criteria such as skills, ability to lift weights, gender and education. This produces a score which indicates how fit the candidate is for the job. In a candidate selection program for removal companies, where ability to lift weights is a favored requirement, hence the source for bias, Datta’s program analyzed how likely is this bias reflected in the score assigned to each application. The program randomly changed the gender and the weight applicants said they could lift in their application, both crucial parameters for the job. If there was no change in the number of women that were pre-selected by the AI for interviews previously, then it is not the changed parameters that determined the hiring process.
As history has shown us, there are hidden pitfalls beyond the general biases in AI systems. Defense and intelligence agencies are overwhelmed by the amount of data generated by surveillance and monitoring systems. An individual being tracked can form unmanageable number of related networks comprising machines and other individuals and keeping a track of all possible nodes of communication multiplied by several hundred thousand subjects can and does become overwhelming. In most glaring cases, certain individuals have slipped through the investigative net, have gone on to inflict severe and long lasting damage through acts of terror. Analysts from one of America’s spy agencies and arguably leading global agency, the NSA, are already overwhelmed by the recommendations of old-fashioned pattern-recognition software pressing them to examine certain pieces of information. Many times its just that the system flags the right individual at the right times, however human analysts or the investigators assigned to probe deeper do not trust the data they are being shown by the software. Having clear explanation of why such individual is flagged and the accurate reasons behind the flag would help convince the investigator and provide rationale for action.
Trevor Darrell’s AI research group at the University of California, Berkeley, conducted extensive research with software trained to recognize different species of birds in photographs. Instead of merely identifying, say, a Western Grebe, the software also explains the logic behind its choice – why it thinks the image in question shows a Western Grebe is because the bird has a long white neck, a pointy yellow beak and red eyes.
Through a combination of art, research, policy guidance and media advocacy, the Algorithmic Justice League is leading a cultural movement towards equitable and accountable AI.
At IBM, through research dedicated to Mitigating human bias in AI, the MIT-IBM Watson AI Lab’s efforts are drawing on recent advances in AI and computational cognitive modeling, such as contractual approaches to ethics, to describe principles that people use in decision-making and determine how human minds apply them. The goal is to build machines that apply certain human values and principles in decision-making.
The Gender Shades project evaluates the accuracy of AI powered gender classification products through collaboration with Microsoft, Google and IBM.

Picture Credit: Google Images
Conclusion
The above biases are not alone. Nor do they represent a significant sample. Observers generally unanimously believe that these are just drops in an ocean of biases living on and growing within the systems collectively known as artificial intelligence.
The creators of technology have a living relationship with the technology they create. Machine learning and intelligent systems today take off after their inventors in many cases where the cultural and social rules to inclusion of ethical perspectives, the creators of such systems lend more to it than just their competence. In a way, artificial intelligence reflects the values of its creators. Familiar biases, old stereotypes, vision of external factors and an unfettered outlook of the world have known to become real, tangible traits while a system free of such biases and beliefs exists only in theory books.
As some view, this is essentially a fight between conflicting interests. On one hand there are people who are largely interested in maximizing the ROI on investment in technology, even as they mistakenly and painfully ignore the perils from such mindless pursuit of short term goals, while on the other hand there are people who are impacted by the outcomes of biased systems. As in any social-economic conflict, there are people who are unaffected by these biases, shielded by such factors which are favorably treated in the machine learning algorithms, hence are not bothered by the outcomes. At the same time, there are people who though unaffected today, realize the pitfalls and perils form such unfettered misplaced prioritization of developing AI and support the introduction of tighter controls around the way Artificial Intelligence is monitored, controlled and regulated. In a lot of ways, this is also a conflict where those who are aware of technology trends and possess insights must act on the behalf of those who are unaware though may be affected by implications of such biases in AI.
Automated systems are not inherently neutral. They reflect the priorities, preferences, and prejudices – the coded gaze – of those who have the power to mold artificial intelligence.
We all have an interest in creating robust technologies, AI systems, and other platforms that make our tasks easier and efficient. Further, an understanding of how the data is collected, and the purpose for which it is being used, is paramount to understanding where it can fail or be misused. On the one hand, we may seek to improve AI to limit the very serious consequences of bias and discrimination — for example, a self-driving car that fails to detect certain pedestrian faces or a greater likelihood that people with darker skin are misidentified as criminal suspects by the police. At the same time, we must continue to call into question whether that use is supported by our values and should therefore be permitted at all. If we focus only on making improvements to data-sets and machine learning and computational processes, we risk creating systems that are technically more accurate but also more capable of doing harm at an unseen, unmitigated levels.